As the migration to 10Gb Ethernet moves forward, many data centers are looking to converge network and storage I/O to fully utilize a ten-fold increase in bandwidth. Industry discussions continue regarding the merits of 10GbE iSCSI and FCoE. Some of the key benefits of both protocols were presented in an iSCSI SIG webcast that included Maziar Tamadon and Jason Blosil on July 19th: Two Storage Trails on the 10Gb Convergence Path
It’s a win-win solution as both technologies offer significant performance improvements and cost savings. The discussion is sure to continue.
Since there wasn’t enough time to respond to all of the questions during the webcast, we have consolidated answers to all of them in this blog post from the presentation team. Feel free to comment and provide your input.
Question: How is multipathing changed or affected with FCoE?
One of the benefits of FCoE is that it uses Fibre Channel in the upper layers of the software stack where multipathing is implemented. As a result, multipathing is the same for Fibre Channel and FCoE.
Question: Are the use of CNAs with FCoE offload getting any traction? Are these economically viable?
The adoption of FCoE has been slower than expected, but is gaining momentum. Fibre Channel is typically used for mission-critical applications so data centers have been cautious about moving to new technologies. FCoE and network convergence provide significant cost savings, so FCoE is economically viable.
Question: If you run the software FCoE solution would this not prevent boot from SAN?
Boot from SAN is not currently supported when using FCoE with a software initiator and NIC. Today, boot from SAN is only supported using FCoE with a hardware converged networked adapter (CNA).
Question: How do you assign priority for FCoE vs. other network traffic. Doesn’t it still make sense to have a dedicated network for data intensive network use?
Data Center Bridging (DCB) standards that enable FCoE allow priority and bandwidth to be assigned to each priority queue or link. Each link may support one or more data traffic types. Support for this functionality is required between two end points in the fabric, such as between an initiator at the host with the first network connection at the top of rack switch, as an example. The DCBx Standard facilitates negotiation between devices to enable supported DCB capabilities at each end of the wire.
Question: Category 6A uses more power that twin-ax or OM3 cable infrastructures, which in large build-outs is significant.
Category 6A does use more power than twin-ax or OM3 cables. That is one of the trade-offs data centers should consider when evaluating 10GbE network options.
Question: Don’t most enterprise storage arrays support both iSCSI and FC/FCoE ports? That seems to make the “either/or” approach to measuring uptake moot.
Many storage arrays today support either the iSCSI or FC storage network protocol. Some arrays support both at the same time. Very few support FCoE. And some others support a mixture of file and block storage protocols, often called Unified Storage. But, concurrent support for FC/FCoE and iSCSI on the same array is not universal.
Regardless, storage administrators will typically favor a specific storage protocol based upon their acquired skill sets and application requirements. This is especially true with block storage protocols since the underlying hardware is unique (FC, Ethernet, or even Infiniband). With the introduction of data center bridging and FCoE, storage administrators can deploy a single physical infrastructure to support the variety of application requirements of their organization. Protocol attach rates will likely prove less interesting as more vendors begin to offer solutions supporting full network convergence.
Question: I am wondering what is the sample size of your poll results, how many people voted?
We had over 60 live viewers of the webcast and over 50% of them participated in the online questions. So, the sample size was about 30+ individuals.
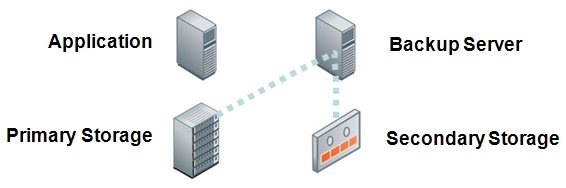
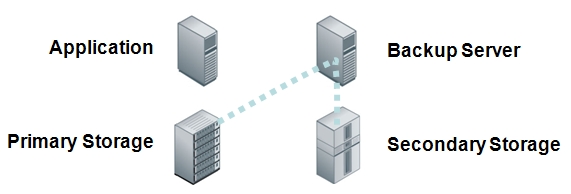
Question: Tape? Isn’t tape dead?
Tape as a backup methodology is definitely on the downward slope of its life than it was 5 or 10 years ago, but it still has a pulse. Expectations are that disk based backup, DR, and archive solutions will be common practice in the near future. But, many companies still use tape for archival storage. Like most declining technologies, tape will likely have a long tail as companies continue to modify their IT infrastructure and business practices to take advantage of newer methods of data retention.
Question: Do you not think 10 Gbps will fall off after 2015 as the adoption of 40 Gbps to blade enclosures will start to take off in 2012?
10GbE was expected to ramp much faster than what we have witnessed. Early applications of 10GbE in storage were introduced as early as 2006. Yet, we are only now beginning to see more broad adoption of 10GbE. The use of LOM and 10GBaseT will accelerate the use of 10GbE.
Early server adoption of 40GbE will likely be with blades. However, recognize that rack servers still outsell blades by a pretty large margin. As a result, 10GbE will continue to grow in adoption through 2015 and perhaps 2016. 40GbE will become very useful to reduce port count, especially at bandwidth aggregation points, such as inter-switch links. 40Gb ports may also be used to save on port count with the use of fanout cables (4x10Gb). However, server performance must continue to increase in order to be able to drive 40Gb pipes.
Question: Will you be making these slides available for download?
These slides are available for download at www.snia.org/?
Question: What is your impression of how convergence will change data center expertise? That is, who manages the converged network? Your storage experts, your network experts, someone new?
Network Convergence will indeed bring multiple teams together across the IT organization: server team, network team, and storage team to name a few. There is no preset answer, and the outcome will be on a case by case basis, but ultimately IT organizations will need to figure out how a common, shared resource (the network/fabric) ought to be managed and where the new ownership boundaries would need to be drawn.
Question: Will there be or is there currently a NDMP equivalent for iSCSI or 10GbE?
There is no equivalent to NDMP for iSCSI. NDMP is a management protocol used to backup server data to network storage devices using NFS or CIFS. SNIA oversees the development of this protocol today.
Question: How does the presenter justify the statement of “no need for specialized” knowledge or tools? Given how iSCSI uses new protocols and concepts not found in traditional LAN, how could he say that?
While it’s true that iSCSI comes with its own concepts and subtleties, the point being made centered around how pervasive and widespread the underlying Ethernet know-how and expertise is.
Question: FC vs IP storage. What does IDC count if the array has both FC and IP storage which group does it go in. If a customer buys an array but does not use one of the two protocols will that show up in IDC numbers? This info conflicts SNIA’s numbers.
We can’t speak to the exact methods used to generate the analyst data. Each analyst firm has their own method for collecting and analyzing industry data. The reason for including the data was to discuss the overall industry trends.
Question: I noticed in the high-level overview that FCoE appeared not to be a ‘mesh’ network. How will this deal w/multipathing and/or failover?
The diagrams only showed a single path for FCoE to simplify the discussion on network convergence. In a real-world, best-practices deployment there would be multiple paths with failover. FCoE uses the same multipathing and failover capabilities that are available for Fibre Channel.
Question: Why are you including FCoE in IP-based storage?
The graph should indeed have read Ethernet storage rather than IP storage. This was fixed after the webinar and before the presentation got posted on SNIA’s website.